LevelDB 04: Compact
目录:
1. 为什么要compaction?
compaction可以提高数据的查询效率,没有经过compaction,需要从很多SST file去查找,而做过compaction后,只需要从有限的SST文件去查找,大大的提高了随机查询的效率,另外也可以删除过期数据。
删除过期数据? 比如 相同key, 不同时期的value?
2. 压缩基础
https://github.com/facebook/rocksdb/wiki/RocksDB-Basics
The three basic constructs of RocksDB are memtable, sstfile and logfile. The memtable is an in-memory data structure - new writes are inserted into the memtable and are optionally written to the logfile. logfile是可选的. The logfile is a sequentially-written file on storage. When the memtable fills up, it is flushed to a sstfile on storage and the corresponding logfile can be safely deleted. The data in an sstfile is sorted to facilitate easy lookup of keys.
When a memtable is full, its content is written out to a file in Level-0 (L0). RocksDB removes duplicate and overwritten keys in the memtable when it is flushed to a file in L0.
3. The Universal Style Compaction 和 The Level Style Compaction 的区别?
leveled compaction是rocksdb默认的压缩方式.[2]
The Universal Style Compaction 属于 "size tiered" 或称 "tiered" 方式.
Here is an example of a typical file layout:
Level 0: File0_0, File0_1, File0_2
Level 1: (empty)
Level 2: (empty)
Level 3: (empty)
Level 4: File4_0, File4_1, File4_2, File4_3
Level 5: File5_0, File5_1, File5_2, File5_3, File5_4, File5_5, File5_6, File5_7
效果上 lower write amplification, trading off read amplification and space amplification.
"tiered" waits for several sorted runs with similar size and merge them together. 待攒够几个sst文件后,
4. Leveled-Compaction
https://github.com/facebook/rocksdb/wiki/RocksDB-Basics
对于The Level Style Compaction, Files in L0 may have overlapping keys, but files in other layers do not. A compaction process picks one file in Ln and all its overlapping files in Ln+1 and replaces them with new files in Ln+1.
awakening-fong注释: memtable满了写L0, 之后, memtable又满了又写L0, 这样, L0就存在重叠的keys.
其他层不会有重叠, 因为L0到L1会合并重叠的区域, 以此类推.
未知问题: 对于The Universal Style Compaction, 是怎样的情况?
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
A special level-0 (or L0 for short) contains files just flushed from in-memory write buffer (memtable). 由内存刚冲刷下来的是写到level 0.
当L0的文件个数达到 level0_file_num_compaction_trigger 后, L0的文件就会被合并到L1中.
这样, 可能导致L1的文件大小超过最大值. 那么, 会至少挑选L1中的一个, 与L2中重叠的区域进行合并. (L1就少了刚才挑选出来的那个文件).
然后, 可能的导致L2的文件超过限制, 如此重复.
Multiple compactions can be executed in parallel if needed:

(本段落可略过) However, L0 to L1 compaction cannot be parallelized. In some cases, it may become a bottleneck that limit the total compaction speed. In this case, users can set max_subcompactions to more than 1. In this case, we'll try to partition the range and use multiple threads to execute it. 可以考虑多线程进行压缩
https://github.com/google/leveldb/blob/master/doc/impl.md
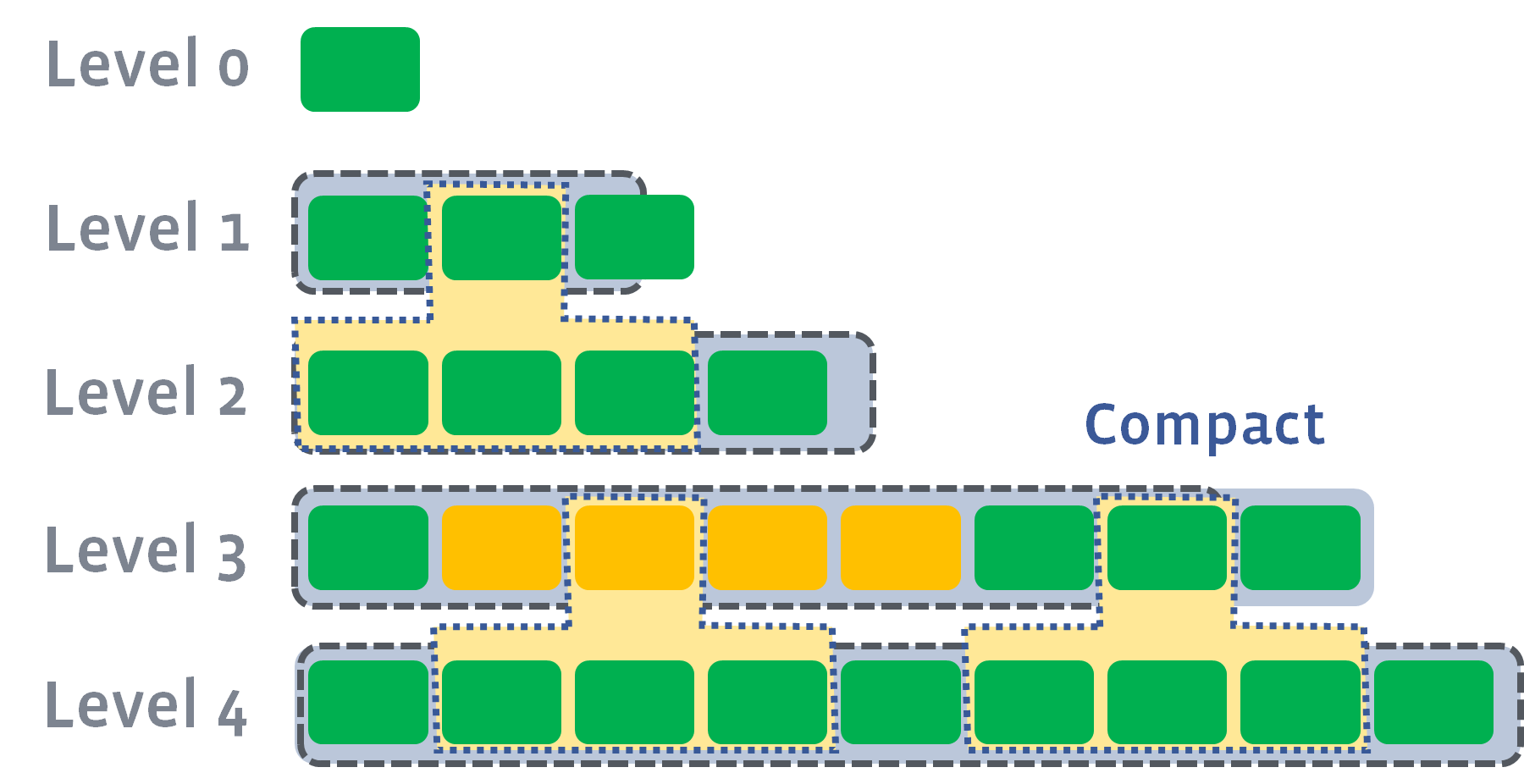
Files in the young level may contain overlapping keys. 较小level的文件间可能包含重叠的key. However files in other levels have distinct non-overlapping key ranges. Consider level number L where L >= 1. When the combined size of files in level-L exceeds (10^L) MB (i.e., 10MB for level-1, 100MB for level-2, ...), one file in level-L, and all of the overlapping files in level-(L+1) are merged to form a set of new files for level-(L+1). 当L层的大小超过限制时, L层的某一个文件 和 L+1层上所有重叠的文件被合并, 形成新的位于L+1层的文件. These merges have the effect of gradually migrating new updates from the young level to the largest level using only bulk reads and writes (i.e., minimizing expensive seeks). 这个合并, 在效果上, 逐渐将新的更新从较小的level迁移到较大的level, 这样, 后续查询消耗较小的disk seek.
When the size of level L exceeds its limit, we compact it in a background thread. The compaction picks a file from level L and all overlapping files from the next level L+1. 压缩过程会从L层挑选一个文件, 然后并从L+1层中选出所有重叠的文件. Note that if a level-L file overlaps only part of a level-(L+1) file, the entire file at level-(L+1) is used as an input to the compaction and will be discarded after the compaction. 压缩过程会从L层挑选一个文件, 然后并从L+1层中选出所有重叠的文件. Aside: because level-0 is special (files in it may overlap each other), we treat compactions from level-0 to level-1 specially: a level-0 compaction may pick more than one level-0 file in case some of these files overlap each other. 在pick level-0 层时, 可能会挑选大于1个level-0 的文件, 如果这些level-0 的文件间存在重叠的情况.
A compaction merges the contents of the picked files to produce a sequence of level-(L+1) files. 产生一系列 level-(L+1)的文件s. We switch to producing a new level-(L+1) file after the current output file has reached the target file size (2MB). 如果这个level-(L+1)文件超过大小限制, 那么, 继续合并到另外一个level-(L+1). 比如, L2合并到L3的文件File3_1, 合并一会儿后, 结果File3_1文件大小超过限制, 故换到文件File3_2. We also switch to a new output file when the key range of the current output file has grown enough to overlap more than ten level-(L+2) files. 如果生成的L+1的key范围太广, 也会切换到新文件. This last rule ensures that a later compaction of a level-(L+1) file will not pick up too much data from level-(L+2). 这个规则确保后续对level-(L+1) 压缩时, 参与的level-(L+2)不会太多. awakening-fong注释: 若仅生成单个新的level-(L+1)文件, 那么, 和这个体积大的文件 重叠的level-(L+2)就可能比较多, 也就是这里说的 pick up too much data from level-(L+2).
Compactions for a particular level rotate(循环) through the key space. In more detail, for each level L, we remember the ending key of the last compaction at level L. The next compaction for level L will pick the first file that starts after this key (wrapping around to the beginning of the key space if there is no such file). 对每一层, LevelDB会记住上回对level L压缩的尾部的key. 下一回对level L压缩时, 会挑选 紧挨着上回key的文件. awakening-fong注释: 也就是leveldb中的compact_pointer_.
https://github.com/facebook/rocksdb/wiki/Compression
LZ4 和 Snappy We believe LZ4 is almost always better than Snappy. We leave Snappy as default to avoid unexpected compatibility problems to previous users. LZ4/Snappy is lightweight compression so it usually strikes a good balance between space and CPU usage.
4.1 leveldb的DBImpl::DoCompactionWork
DBImpl::DoCompactionWork
|--versions_->MakeInputIterator ==> VersionSet::MakeInputIterator
|--input->SeekToFirst()
|--遍历input
| |--简化, 这里忽略CompactMemTable的情况
| |--ParseInternalKey() 得到sequence, type, user_key
| |--根据seq, drop老旧的数据
| |--last_sequence_for_key 记录本次的seq
| |--若需要, 则创建文件
| |--compact->builder->Add(input->key(), input->value())
| |--攒够后, FinishCompactionOutputFile
| | |--compact->builder->Finish
| | | |--Write metaindex block, index block, footer
| | |--同步文件
|--InstallCompactionResults
| |--修改VersionEdit信息
5. 参考资料
[1] https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
[2] https://github.com/facebook/rocksdb/wiki/Universal-Compaction
[3] https://github.com/google/leveldb/blob/master/doc/impl.md
本文地址: https://awakening-fong.github.io/posts/database/leveldb_04_compact
转载请注明出处: https://awakening-fong.github.io
若无法评论, 请打开JavaScript, 并通过proxy.
blog comments powered by Disqus